Category Archives: Java
Ready for todays webinar about OpenNTF Essentials?
I hope that you have already dowloaded OpenNTF Essentials and at least installed on your development computer. If not, it’s a 5 minute job as you can see in this youtube video http://youtu.be/EUrLfJcCQhY (starting 12:00).
In Todays webinar, Mark will cover some cool stuff about debugging and Nathan takes a deep dive into the OpenNTF Domino API. My part will be about some cool @nnotations. Imagine this:
Your are writing a call center application and you have designed the “Call” object as a java object according the java bean specification. With the ObjectData Source from the ExtLib are you know ready to edit each field of this java object, but now you have to save….. and read …. and delete ….. the object from the database.
I will show you in todays webinar how you can do this with writing only “3 or 4” lines of code 🙂
I hope you will join us, today 10:30 EST, register now!
Off to Boston
It’s a great honor to be invited to the IBM Leadership Alliance Conference at Boston. So I’m a bit nervious. But I’ve some great news to share with other Partners and IBM about OpenNTF and the next big thing.
When I’m back, is a heavy loaded week planed. There are several topics to finish:
- Some IP Stuff for the next big thing
- Review and update our IBM Cconnections backup concept
- find the price plan for our new serivce that we will offer at WebGate and do some planing stuff for the lauch event
- And hopefully a lot of coding
As you see a lot of things to cover, so my investigations in a buildserver has to wait until the weekend, but I hope that I can do some tutorials about the webgate ninja style.
PS: Writing blogs with my IPad on the airport is less fun then coding on the airport with my macbook
Yes you can….
Today we will have a webinar about POI4XPages. POI4XPages is plugin that enhance and extend the XPages / XWork platform. It gives you the freedom to produce Word and Excel files direct from a application.
We are getting feedback around the globe for the plugin and it’s amazing to hear that developers use POI4XPages to deliver excellent solutions to their customers. POI4XPages is under the Apache V2 License, that means YES YOU CAN ….
- use it in any project (see this wiki entry http://en.wikipedia.org/wiki/Apache_License)
- build a solution or a product and sell this product
- getting the source code and extend it
- taking parts of the source code to solve a problem
- bundle it to a new set of plugins for the XPages / XWork platform
Bundling POI4XPages to a new set of plugins? Sounds like a good idea! Stay tuned we are thinking about some thing real cool @ OpenNTF. I hope that I can blog about it this week.
POI4XPages Version 1.2.4 is out
We have released the Version 1.2.4 of the popular POI4XPages framework. The new release contains the following new features:
1. Building Tables in Document:
The document control has a new property called tables. If a table is defined, POI4XPages will replace the existing table on the document with this new tabel. See the example how it works -> docx_document_table.xsp

2. Execute POI Actions
Since version 1.1.6 is the Apache POI API available to the programmers. But in some situations it’s needed to execute Actions with privileged access. To give you the power of this in your hand, we introduce the AbstractPOIPowerAction.
How it works? See the sample file_upload.xsp and the Java classes.
3. Export Views as CSV or Workbook
You have the view designed and need the data as CSV or Workbook? The SimpleViewExport provide this behavior.
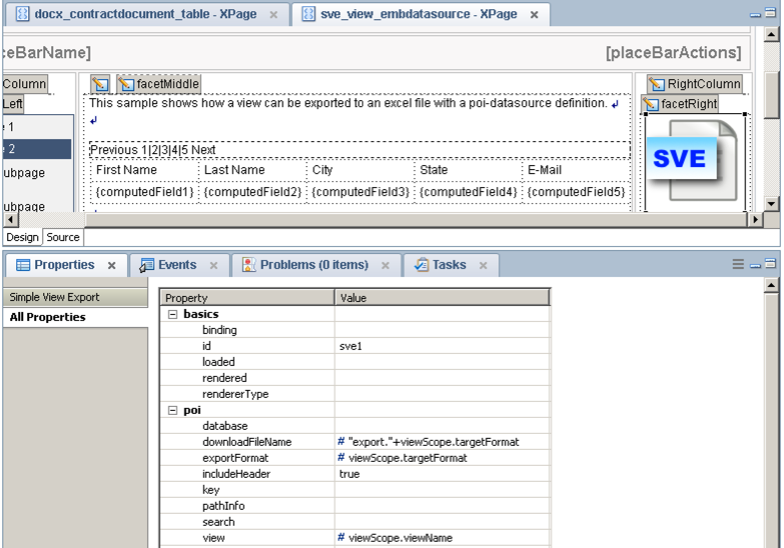
Examines the example database. See what you can do with all the controls.
Download the project form OpenNTF.
Visit the install guide and the documentation.
Report bugs and request on GitHub.
And as always… HAVE FUN
Christian
The “ninja-style” programming model by WebGate
First I’ve to excuse that we are so selfish to call our programming model ninja-style. It was happened based on the fact, that we have programmed ninjas in internal programming course. But the term ninja-style was established and if you gave something a name, it’s very hard to change it (Maybe you have seen Monster.Inc by Pixar, then you know what I mean).
Our intention is to make programming for XPages as much fun as possible. And fun means in the case of programming: Having success, with less of effort and stress.But the ninja-style has also to do with leaving the comfort zone and go out from this protected workshop in which the most of the domino developers where living. XPages requires a complete new set of skills. On the front end part are you faced with: HTML5, JavaScript, CSS, DOJO (and that’s only the beginning) and of course SSJS for the binding part. On the backend is Java the most required skills, that you should have. But you have also to learn about data sources, controls, data binding and something called JSF life-cycle.
Definitely a lot of topics to cover and the most of us are not geniuses, specially universal genius. It’s a matter of fact that it is easier to split and separate the topics. Because of this we have introduced the N-Tier architecture to our programming model. We have separated the front end stuff, from the back-end stuff.
The front end covers all the presentation (Presentation Layer)
Typically our front end developers are brilliant in arranging all the controls in the XPages and they are mostly virtuous in JavaScript, CSS and Dojo. They know about the “beans” as far as they have to know how to use them as API to the model and the business logic. They don’t care, how object are loaded and stored, they don’t care about how processes and logic are executed, as long all is working correct.
The backend covers all the model and business logic (Business logic Layer)
The back-end guys do all the brilliant stuff with the model of the data and all the processes. Mostly they are Java Cracks or on the way to it. They care about good backend performance and have read the book “design pattern” by the gang of for. No interface and connection to any backend is to complex for them, but do not let them do any HTML stuff.
But where are the storage guys?
At this point, some of the core features of the XPT cames to action. The DSS of the XPT solves all the storage stuff.
But keep this: Having success with XPages has to be about simplification. Our first step was to separate front end from back-end.
To be continued >>>
Christian
Rendering HTML Code with DJANGO and DOJO
One of the things that I like about dojo is the django rendering engine. It provides an easy way to build HTML Templates and let you render values form a json object. The following example of a template is used to loop through a json array response.
<div>
{% for entry in feed.entries%}
<div style=”height: auto;”>
<div>
<div>{{entry.created}}</div>
<h2>
<a target=”_blank” href=”{{entry.link}}”>{{entry.title}}</a>
</h2>
</div>
<div>
<div>
{{entry.content|safe}}
</div>
</div>
</div>
{%endfor%}
</div>
This code is used in the dojo widget:
dojo.provide(“xptrss.list.feedcontroller”);
dojo.require(“dijit._Widget”);
dojo.require(“dojox.dtl._Templated”);
dojo.declare(“xptrss.list.feedcontroller”, [ dijit._Widget, dojox.dtl._Templated ], {
proxyurl:null,
feed : null,
templateString : dojo.cache(“xptrss.list.feedcontroller”, “../../html/rssTemplate.html”),
targetid: null,
postCreate: function() {
var mySelf = this;
var xhrArgs = {
url : mySelf.proxyurl,
handleAs : “json”,
preventCache : true,
load : function(data) {
mySelf.feed = data;
mySelf.render();
dojo.style(mySelf.targetid +”_feedLoader”, {
display : “none”
});
},
error : function(error) {
alert(error);
}}
var deferred = dojo.xhrGet(xhrArgs);
}
});
With the statement templateString : dojo.cache(“xptrss.list.feedcontroller”, “../../html/rssTemplate.html”) the html will be loaded. The “postCreation()” handles the loading of the values. With “mySelf.render()” the loaded JSON object will be applied to the HTML Template and the django engine loops through all entries and applies the code between {% for …. } {%endfor%} for each entry.
But what if an element in an entry (like the content value) is pure HTML Code?
The django engine is so clever and escapse all content correct, but we need the content unescaped in this particular case. The statement {{entry.content|safe}} does the trick!
This is code from our new project XPages Toolkit.
POI4XPages 1.1.5 delivers PDF Creation of Documents and computeValue for Row/Column Export
Today we release the version 1.1.5 of POI4XPages. The real big enhancement is the PDF-export for Wordfiles. Thanks to the programmers of docx4j and Apache FOP, we were able to integrate these projects into POI4XPages.
Read also the blogpost about the odyssey of integration I wrote yesterday.
An other enhancement is computeValue for row and column export. Each cell can now be calculated. Have a look at the updated example database to see how to use this.
Have fun and thanks to my team for making this happen.
The odyssey of loading a class in a Eclipse plugin – or how we integrated docx4j in POI4XPages
While I was visiting the IBMConnect in Orlando, Lena investigated about how to convert Word files into PDFs. Because of licence reasons, we decide to use docx4j in conjunction with Apache FOP. Both projects are licensed using the Apache V2 license, in opposition to iText.
Lena built a prototype and tested it with Eclipse against the current JVM of the domino server. All worked fine and we started to integrate docx4j as new plugin project in POI4XPages. We also tested the plugin against a regular java programm. Everything worked fine.
The next step was to integrate the creation of the PDF into the UIDocument and the DocumentGeneration classes. This worked fine as well but when we started the conversion it seemed that docx4j has lost its ‘Focus’. The conversion failed because it could not find ‘docx4j.properties’ and ‘log4j.properties’.
After several attempts of building source code based of docx4j and debugging and patching it, I figured out the problem during the night. To make it short, here is the analysis of what had happened:
The problem:
The conversion function in the eclipse plugin was executed by a ClassLoader from Domino. This is not bad at all. But in this case, the context was absolutly relevant to find all the resource files in the docx4j.jar and all the classes. JAXB seems also to be classloading context sensitiv.
The solution:
We changed the ClassLoader context during the PDF conversion as you can see in the code below.
The red marked code does the trick. currentThread.setContextClassLoader( Activator.class.getClassLoader() ) changes the ClassLoader context to the context of the plugin.
When the conversion is done we change the ClassLoader context back to the old context.
public void buildPDF(InputStream isDocument, OutputStream osTarget)
throws PDFException {
Logger logCurrent = LoggerFactory.getLogger(this.getClass().getCanonicalName());
boolean blRC = true;
Exception eRESP = null;
Thread currentThread = Thread.currentThread();
ClassLoader clCurrent = currentThread.getContextClassLoader();
logCurrent.info(“Current thread class loader is: ” +clCurrent);
try {
currentThread.setContextClassLoader(Activator.class
.getClassLoader());
logCurrent.info(“Getting WordprozessingPackage”);
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage
.load(isDocument);
logCurrent.info(“Getting PdfSettings”);
// 2) Prepare Pdf settings
PdfSettings pdfSettings = new PdfSettings();
// 3) Convert WordprocessingMLPackage to Pdf
logCurrent.info(“Getting PdfConversion”);
PdfConversion converter = new Conversion(wordMLPackage);
logCurrent.info(“do Conversion”);
converter.output(osTarget, pdfSettings);
} catch (Exception e) {
eRESP = e;
logCurrent.log(Level.SEVERE, “Error during PDF Conversion: “+e.getMessage(),e);
blRC = false;
} finally {
currentThread.setContextClassLoader(clCurrent);
}
if (!blRC) {
throw new PDFException(“Error during FOP PDF Generation”, eRESP);
}
}
A happy ending to a long odyssey.
The new release of POI4XPages will be released later this week, together with some bug fixes and new features.
New Documentation for POI 4 XPAGES available
Today we released some howtos for POI 4 XPAGES on my.webgate.biz/poi.documentation.
Thanks Lena for sharing this with us.
