Sometimes, small things are very satifiying and enjoyable, and this one is such a thing.
The setup / probleme / situation…
You have this field, where you can select a user for your application. The behavior should be simple. You type the start of the first name and…. voilà all user are available as a drop down. If you use Angular 11 and Material Design, your code for the HTML will look like this:
<mat-form-field class="recipientSearch"> <input type="text" placeholder="Suche..." matInput formControlName="recipientSearch" [matAutocomplete]="auto" /> <mat-autocomplete #auto="matAutocomplete" (optionSelected)="select($event)"> <mat-option *ngFor="let recipient of filteredRecipients | async" [value]="recipient"> <div class="namePicker"> <img class="avatar" [src]="getProfileImage(recipient) | async" (error)="getAltPicture($event)" /><span class="nameEntry">{{ recipient.displayValue }}</span> </div> </mat-option>
</mat-autocomplete> </mat-form-field>
2 Things to mention here:
– formControlName=”recipientSearch” means that we have in our controller a FormControl that is bound to the input field
– *ngFor=”let recipient for filteredRecipients | async” tells you that there is an observable with the result of the some service involved.
On the controller (typescript) side is the following code inplace:
this.recipientSearch.valueChanges.subscribe((value) => {
if (value === '') {
this.filteredRecipients = of([]);
} else {
this.filteredRecipients = this.userService.searchRecipient(value);
} });
Very simple code. If a value is changed in the recipientSearch, we will get informed and we do call the userService to searchRecipient. And there we do some simple stuff and call the MS-Graph API via httpClient. Something like this here:
const graphUsersEndpoint = 'https://graph.microsoft.com/v1.0/users';searchRecipient(search: string): Observable<User[]> {
const searchQuery = graphUsersEndpoint + "?$filter=startswith(displayName,'" +
search + "') or startswith(mail,'" + search + "') or startswith(surname,'" +
search + "')";
return this.httpClient.get<User[]>(searchQuery).pipe(map((val: any) => val.value));
}
Not huge rocket science.. be aware to set the Bearer token correct (thats something for another blogpost). But there is an issue here. This pattern leads to building unused Oberservables. Let me show you with some slight code modification, what I mean:

I’m logging each generation of the Observable, with the following result in the console:

Searching for John to find John Doe results in 4 Observables and based on my type speed and the Angular Componente Lifecycle, up to 4 calls to the Graph API will be made. To make this visible, I’ve changed the following code:
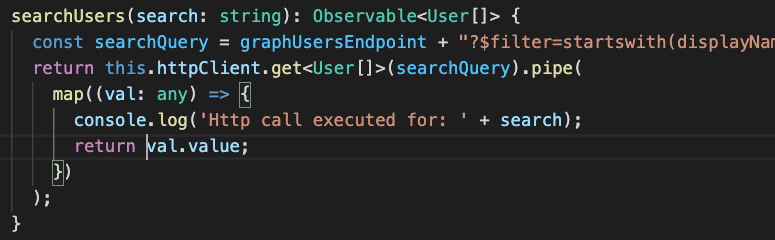
With the correspondig result:
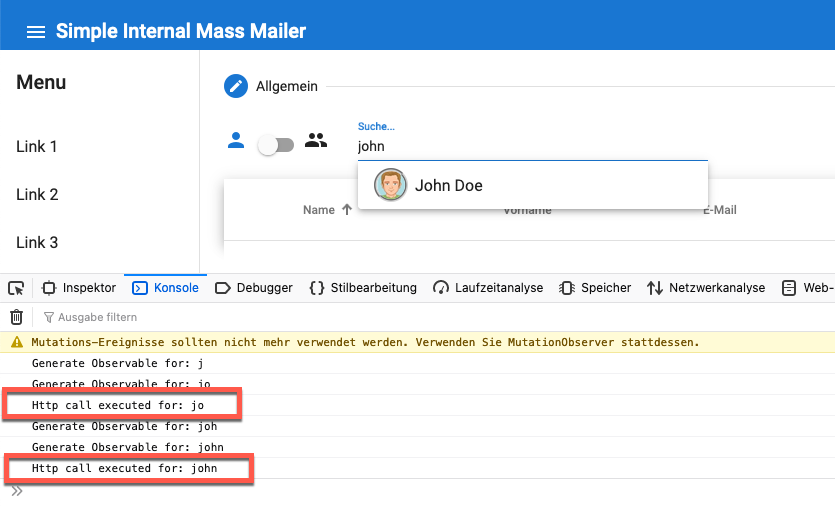
But how to eliminate this unwanted calls? Is there a way to delay or debounce my keyboard entries? You wont believe, but the solution is very simple and charming:

This simple construct of .pipe(debounceTime(500)) has a huge effect on the value that is provided via subscribe. Inside the pipe, debounceTime acts as puffer that delays the output for 500ms if no new value is coming thru the pipe. Saying this, with my normal type speed, I get the following console output:

Simple, charming and very effective. A good reason to understand Observables, pipes and the pipe operators from RxJS.